


This article is part of a series: The Past, Present and Future of OpenSAFELY
- The past, present and future of OpenSAFELY: Introduction
- How OpenSAFELY works
- Co-pilots give newcomers a helping hand
- Standard tools for data preparation, and federated analytics
- Output checking helps to keep private data safe
- The legal basis: ethics, controls and building trust
- Earning and maintaining trust: PPIE and more
- How OpenSAFELY began
- Consequences of COVID-19 and the role of vaccination
- “No other platform comes close”
- The 'unreal' speed of OpenSAFELY
- Using OpenSAFELY to fight antimicrobial resistance
- OpenSAFELY and antibiotics
- Using OpenSAFELY to carry out a randomised trial
- The OpenSAFELY Collaborative
- Some reflections about funding
- What's next for OpenSAFELY?
Electronic health records are made for doctors and patients; and preparing those records for analysis is hard. This process of turning raw records into analysis-ready tables is a common challenge, and often the biggest part of any project using EHR data.
In the past, different teams working on EHR data would each approach the same data preparation job in their own esoteric way. This causes huge problems: even if you could access their code, it would be hard to understand. Furthermore, code for data preparation was generally written to run on one database, in one computer: so if the database changed, or the data moved, then often that hard work had to be thrown away.
We set out to solve those problems by creating new, bespoke, standardised, open source tools that all analysts can use for data preparation. These standard OpenSAFELY data preparation tools are an important feature of the platform’s success.
Firstly, this standardisation means that all researchers are doing the same job in the same way, which is great for efficiency. Users can read and understand each others’ standardised code more easily, so they can check its quality, and re-use it or adapt it if they want to.
Secondly, it means that users’ data preparation code can run in any data centre where OpenSAFELY tools have been installed: it’s no longer tethered to one specific database, in one specific data centre. That’s critical, because it avoids problems like “vendor lock-in” to any one type of database. It also means that it’s worth writing great data preparation code, because you’ll be able to use it for a long time.
But it also helps us deliver one last key innovation from OpenSAFELY: federated analytics.
GPs’ records about their patients are stored in two different places: the two data centres of the two major electronic health record system suppliers, TPP and EMIS. Each GP choses which system to use. We were under pressure not to extract and move large amounts of disclosive GP data around to new locations and data centres, because of issues around privacy and transparency.
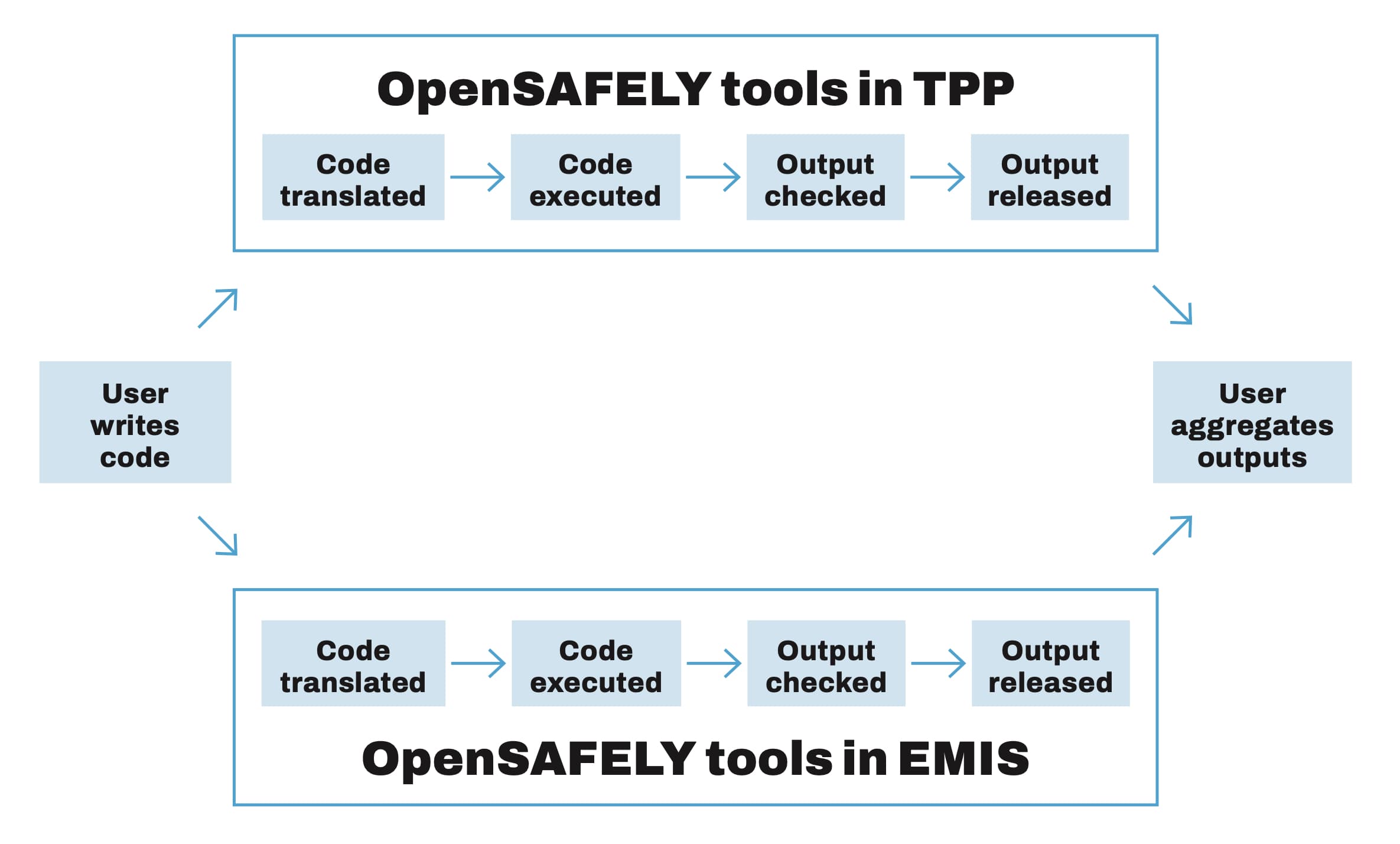
So instead of extracting data to give to users, we devised OpenSAFELY as a way for the code to go to the data. Our standardised data preparation code is a key part of what enables that “nice idea” to work in practice.
You can see this in the picture, below. The same data preparation code is written once, by users. It then travels out to EMIS and TPP’s data centres, where it is automatically translated by the OpenSAFELY tools into code that can work on that data centre’s specific machines and databases. The code runs to completion, and the analyst stitches together the results using their preferred methods.
Making this happen was hard work, requiring deep and creative collaboration between software developers and researchers with extensive knowledge of how electronic health records work, and how they are used in research.
But the hard work paid off. For many years, people have talked about the power of GP data in the NHS, but it’s never previously been possible to access this data at a national scale. By developing tools that can do federated analytics, and manage privacy challenges, we were able to produce landmark papers analysing the whole population’s GP records for the first time in history.
Using these tools, papers have now been published to explore all kinds of important questions: which kinds of patients have, and have not, been vaccinated against COVID-19; which types of patients are being coded as having “Long COVID” most commonly; and whether there were changes in adherence to guidelines on safe prescribing during and after the pandemic. We look forward to working with our users to produce many more.